
%20(2).png)
There is a test that cuts through most AI vendor claims about autonomous fraud operations in 30 seconds.
Ask: “What is the hardest environment you have ever operated an autonomous system in?”
If the answer is a controlled setting, a simulated benchmark, or a domain with fixed rules, you are looking at impressive engineering. If the answer is a live, regulated banking environment — one in which the adversary adapts in real-time, every decision carries financial and personal consequences, the system must produce outputs that hold up under legal scrutiny, and getting it wrong costs real customers real money — you are looking at something categorically more significant.
This is where autonomous fraud operations sit, and it’s why the science matters before the marketing does.
What makes an environment hard for autonomous AI
The history of AI progress is largely a history of conquering increasingly difficult environments.
Checkers fell in 1994. Chess in 1997. Jeopardy in 2011. Go in 2016. Each breakthrough produced a wave of commentary about machines surpassing human ability. Each, in hindsight, solved a specific class of problem: bounded, fully observable, fixed rules, and a clear definition of winning.
The real world is none of those things.
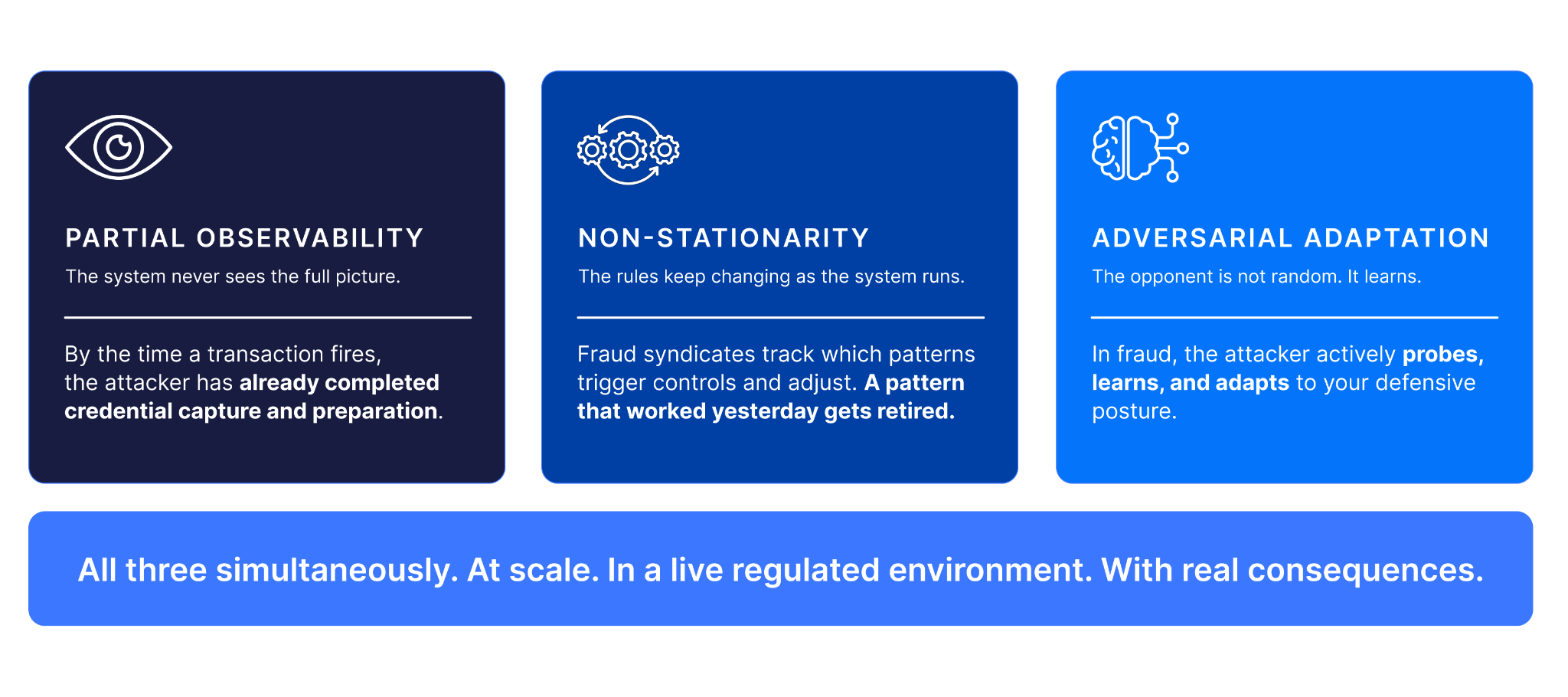
Autonomous systems operating outside controlled environments face a set of scientific challenges that make game-playing look tractable by comparison. The environment is partially observable — the system never has complete information. The environment is non-stationary — the rules change while the system is running. And in adversarial domains, a third challenge arises that has no equivalent in any game: the opponent is not random; it learns.
Fraud is all three simultaneously.
A fraud attack is not a transaction. It is a structured campaign (sometimes days or weeks in construction) executed across thousands of accounts, devices, and sessions. By the time a transaction reaches a bank's detection systems, the attacker has already completed credential capture, session profiling, and social engineering preparation. The system observes the last step of a process it never saw begin.
At the same time, the attack itself is adaptive. Fraud syndicates monitor which patterns trigger controls and adjust accordingly. A pattern that worked yesterday gets retired when it starts producing friction. A new variant gets tested. The ground truth shifts faster than any static model can keep up with.
This is adversarial machine learning in its most demanding applied form. And the scientific community has known for decades that it is orders of magnitude harder than the problems AI solved in games. The question was never whether an autonomous system could operate here. The question was how long it would take to build one that could.
Why autonomous operation is not the same as fast automation
Before the science of autonomous fraud operations can be understood, a clear distinction must be established. It is foundational, and conflating the two terms produces exactly the vendor confusion that currently fills the market.
Automation: speeds up individual steps. An automated investigation assistant can gather evidence faster than a human analyst. An automated alert-scoring system can flag priority cases faster than manual review. Automation is additive. The human is still the workflow's structural dependency.
Autonomy: removes the human as the limiting factor of the entire system. The workflow runs end-to-end without requiring human initiation, human throughput, or human assembly. Humans remain essential, but as the oversight layer, not the processing layer.
This distinction has a precise meaning in multi-agent systems research, the branch of AI science that underpins what is now called agentic AI in banking. A multi-agent system is an environment in which multiple AI agents (each with its own goals, perceptions, and decision logic) coordinate to produce outcomes that no single agent could achieve alone.
The scientific challenge is not building individually smart agents. Any sufficiently trained model can do that in isolation. The challenge of coordination under uncertainty is how multiple autonomous agents share information, resolve conflicts, and produce coherent decisions when each agent sees only part of the picture and the environment is changing.
This is an active research area. The theoretical foundations come from game theory, distributed computing, and reinforcement learning. The practical challenge - making it work reliably in a live regulated environment where every action must be explainable and attributable - is the engineering problem that has taken the longest to crack.
The evidence problem: why raw data is not enough
There is a second scientific challenge underneath the agent coordination problem that most commentary on autonomous AI in banking misses entirely.
Autonomous reasoning is only as good as the evidence it reasons over.
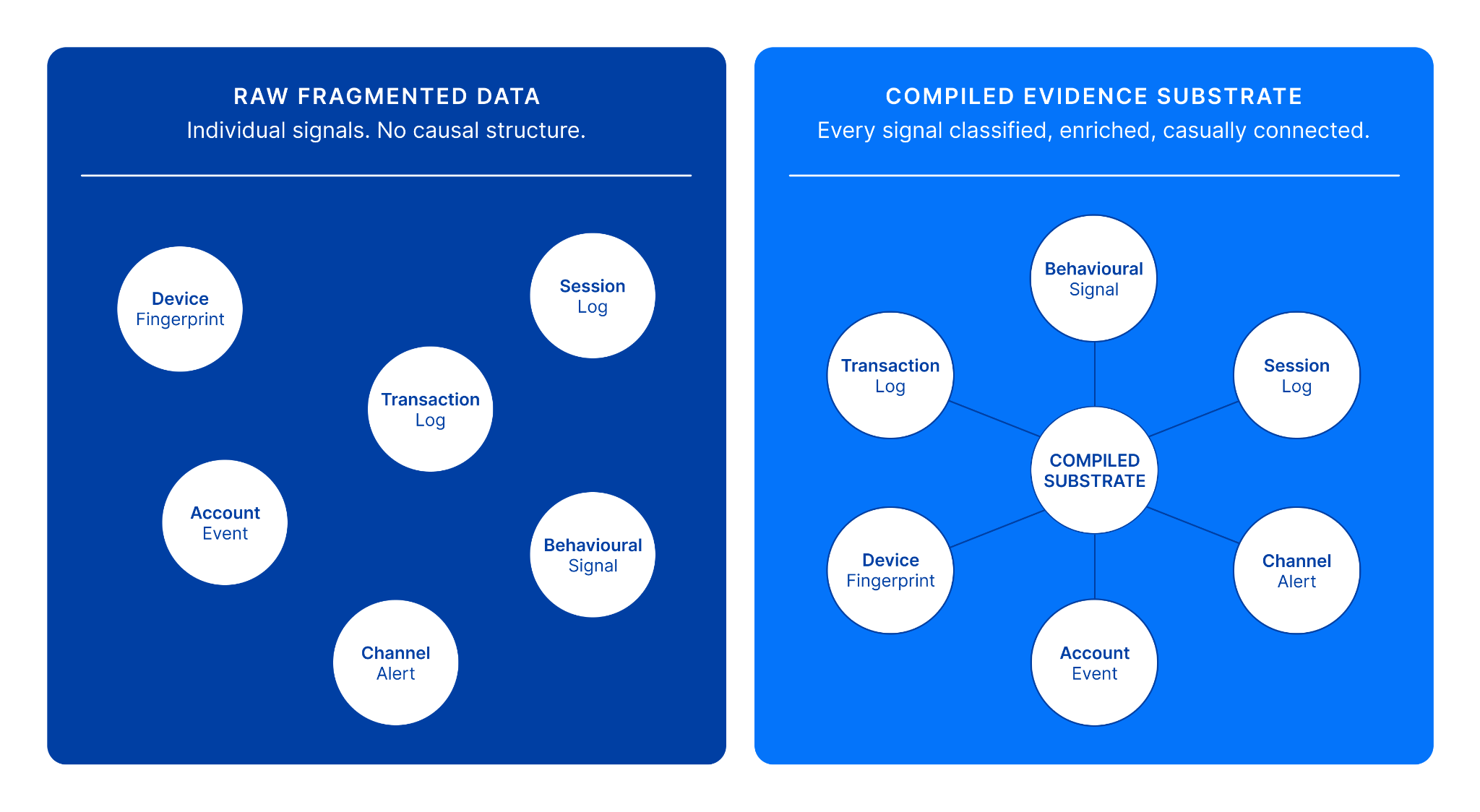
This sounds obvious. In practice, most AI systems deployed in fraud operations today receive data that has been minimally processed: raw transaction records, device fingerprints, and session logs. Individual signals, collected at different times, by different tools, in different formats. The AI then attempts to reason over this fragmented input.
The scientific analogy is asking a radiologist to diagnose a patient from photographs of individual organs taken years apart and stored in different hospitals. The individual images may be high quality. The diagnostic problem is unsolvable because the integrated clinical picture has never been assembled.
Autonomous fraud operations require a different data architecture. Before any autonomous reasoning begins, every signal must be classified, enriched, and causally connected into a unified representation of what is happening in the digital environment. Every actor - device, account, session, channel - must be typed and linked. Every temporal relationship must be preserved. The causal chain from the first anomalous signal to the last transaction must be reconstructable.
This compiled evidence substrate is a continuously updated, causally structured model of everything the system can observe about a living digital environment. It is what the autonomous agents reason over. And its quality determines the quality of every output the system produces.
Building this substrate at scale, maintaining it under live production load, and making it computationally available for real-time multi-agent reasoning; this is one of the deepest engineering challenges in applied AI. Most systems that claim autonomous operation are, in practice, running capable models over incomplete evidence. The outputs are faster. They are not forensic-grade.
What the alignment problem looks like in a bank
There is a third scientific challenge that has received more attention in academic AI research than in financial services, but which is critical to understanding why autonomous fraud operations are genuinely hard to deploy in-house and why getting the governance architecture right is not a compliance task; it is a scientific problem.
The alignment problem asks: how do you build an autonomous system that reliably pursues the goal you intend, rather than the goals that are easiest to optimise?
In a game, the alignment problem is simple. The reward is the score. In a live banking environment, the alignment problem is considerably more complex. The system's goal is not to maximise fraud detection. It is to protect customers, reduce losses, satisfy regulators, preserve customer relationships, and remain explainable under audit, simultaneously in real time against an adversary actively seeking gaps.
The technical solution to this problem in today's deployed systems is a human-on-the-loop architecture. The autonomous system does not make consequential decisions. It produces recommendations — investigations complete, campaigns mapped, actions proposed — that require human authorisation before execution. Every recommendation is logged, timestamped, and traceable back through the evidence chain that produced it.
This is not a governance constraint bolted onto the technology. It is a deliberate design choice that resolves the alignment problem in a regulated environment: the system can be as autonomous as the task requires, while preserving human accountability at every consequential decision point. It is what makes autonomous operation deployable inside a regulated bank without requiring the regulator to trust the machine directly. The regulator trusts the human who reviews the machine's work.
Building this architecture correctly, so that autonomy is genuine, not degraded by the oversight requirement, and so that oversight is meaningful, not theoretical, is a scientific and engineering achievement in its own right.
Autonomous Fraud Operations: where the science is proven
Fraud is the domain where all of these scientific challenges converge. Partial observability, non-stationarity, adversarial adaptation, evidence quality, multi-agent coordination, and alignment under regulatory constraint: fraud operations is the proving ground precisely because it demands all of them simultaneously, at scale, under live conditions, with real consequences.
This is why Autonomous Fraud Operations are the right starting point for the broader category of autonomous risk operations. Fraud is the most difficult form of the problem. If the architecture holds here, it holds everywhere.
The definition is specific by design: Autonomous Fraud Operations is the operating model in which the full fraud lifecycle — detection, investigation, decisioning, response, and learning — runs continuously at machine scale, without human throughput as the limiting factor.
Not automation. Automation makes individual steps faster. Autonomy removes the human as the structural bottleneck of the entire workflow. The difference matters. A lot.
In a human-bound fraud operation, every alert that gets properly investigated requires an analyst. Four to five hours of work per case. Multiply that by the volume of signals modern fraud detection generates — and you get the coverage gap that almost every fraud team quietly accepts as the cost of doing business. Around 25-30% of fraud cases never receive a proper investigation. Not because teams aren't doing their jobs. Because the math no longer works.
Autonomous Fraud Operations changes the math. Every alert is investigated. Every coordinated campaign is reconstructed before the first loss. Detection-rule optimisation happens continuously, without the dependency of a human rules engineer. The function scales with AI, not with headcount.
Humans don't disappear. They move: from clearing queues to reviewing models, from triaging alerts to supervising outcomes. The function still has people. Its capacity is no longer bounded by them.
The scope is specific by design: payment fraud, account takeover, authorised push payment scams, synthetic identity, mule networks, online banking fraud across web and mobile, and the newer wave of AI-generated attacks.
Autonomous Risk Operations: the scientific case for what comes next
Autonomous Risk Operations is the broader category. It is what the fraud-proof is building toward.
It defines an operating model in which the full portfolio of a bank's operational risk functions — fraud, financial crime, conduct risk, internal risk, AI-risk oversight — executes at machine scale, with humans relocated from execution to governance.
The architectural insight is that the substrate, which makes Autonomous Fraud Operations possible (continuous signal correlation, autonomous case construction, regulated workflow execution at machine scale), is not fraud-specific. It is a general-purpose platform for running any regulated operational risk function autonomously. Fraud is the domain where it was first proven to hold. AML, sanctions, and conduct are the domains where the same architecture runs next.
What that means in practice
A bank where the coverage gap disappears not just in fraud, but across the entire operational risk function. Where a suspicious actor surfaced simultaneously across fraud, AML, and conduct lenses, without three separate teams having to connect the dots manually. Where continuous investigation is not a fraud capability. It is the bank's operational model.
The regulatory surface expands accordingly: AMLD6, EU AI Act, DORA, Basel operational risk, on top of everything fraud already carries.
The relationship: not interchangeable, sequential
Most of the market treats Autonomous Fraud Operations and Autonomous Risk Operations as synonyms, with different brand ambitions. The market confusion around these two terms is not just imprecise. It is a scientific error.
Every Autonomous Fraud Operations deployment is a subset of Autonomous Risk Operations. Not every Autonomous Risk Operations deployment is just fraud.
The substrate that runs Autonomous Fraud Operations — continuous correlation, autonomous case construction, regulated workflow execution at machine scale — is architecturally capable of running multiple regulated functions. Fraud is the first one proven. Others follow on the same foundation.
The order matters. Lead with what is proven. Build toward what comes next.
Why this distinction matters
The confusion between these two terms is not just a semantic problem. For institutions evaluating autonomous AI in fraud and risk operations, it has practical consequences.
It changes what proof you should demand
Autonomous Fraud Operations has production proof. At leading EU tier-1 banks, since December 2025: sub-five-minute investigation resolution and zero human intervention in the investigation loop. That proof is dated, specific, and auditable.
It aligns with the regulatory forcing function you actually have today
Online banking fraud has a forcing function right now: PSR mandatory reimbursement, FCA Consumer Duty, and personal accountability for executives mean every CRO in Europe already has fraud losses on their quarterly board dashboard. Autonomous Fraud Operations addresses that conversation directly, with production proof that exists today.
The question to ask
Science does not lie, but language can.
Autonomous Fraud Operations and Autonomous Risk Operations describe real architectural progress. They also describe the territory where vendor claims are hardest to verify because the environments are complex, the timescales are long, and the evidence only becomes available once the system has been running at scale, under live conditions, in a regulated environment.
The right way to evaluate any claim in this space is the same question this article opened with: What is the hardest environment you have ever operated an autonomous system in?
If the answer is a regulated tier-1 banking environment, where every decision is auditable, every output must hold up under legal scrutiny, and the adversary is actively adapting to your defences, ask for the production proof. The date. The institution. The scale. The outcome.
For the institutions thinking beyond fraud, about the full portfolio of operational risk functions, the architecture has already demonstrated it can hold. The question is how quickly the same foundation gets extended.
%20CTA%20Blog%20Banners%20-%20Cleafy%20%20(6).png)
.png)

%20copia%207.png)
%20copia%205.png)